MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
Abstract
Audiovisual arts encompass diverse creative disciplines, including cinema, visual arts, stage performance, and game design, where artistic meaning arises from deliberate combinations of visual, auditory, and narrative elements. True artistic understanding extends beyond recognizing what is depicted to reasoning about why it is expressed through particular creative choices. Despite the strong progress of multimodal large language models (MLLMs), this critical aspect of artistic understanding remains underexplored, as existing benchmarks largely measure perceptual recognition while overlooking reasoning about creative intent. To address this gap, we introduce MuseBench, a comprehensive benchmark designed to evaluate MLLMs on nuanced artistic understanding. It comprises 4,016 questions spanning cinematic arts, static visual arts, stage performing arts, and game arts, distilled from over 10K candidate video essays that pair professional commentary with visual demonstration. Comprehensive zero-shot evaluation of 28 state-of-the-art MLLMs reveals that even the best-performing model achieves only 48.29% accuracy, substantially below human expert performance of 87.18%.
Benchmark Overview

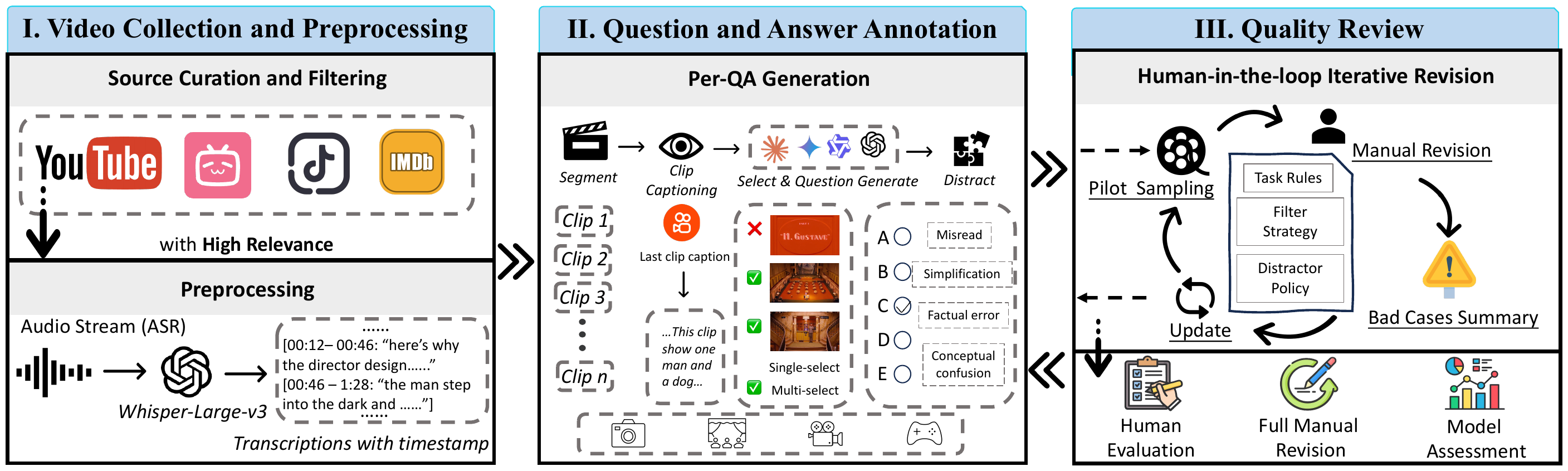
Construction Pipeline
MuseBench is constructed through three phases: (I) video collection and preprocessing with audio transcription, (II) question and answer annotation with adversarial distractor generation, and (III) human-in-the-loop iterative quality review.
Example Questions
Sample questions from each of the four art categories, illustrating single-select and multi-select formats with varying option counts.

Results
Zero-shot evaluation across 28 MLLMs. ACC = Accuracy (%), CAA = Chance-Adjusted Accuracy (%), EM = Exact Match (%). Per-category CAA shown for single-select questions.
| Model | ACC | CAA | EM | Cin. | SVA | SPA | Game |
|---|---|---|---|---|---|---|---|
| Human Expert | 87.18 | 90.98 | 78.00 | 98.74 | 90.13 | 89.42 | 86.15 |
| Proprietary MLLMs | |||||||
| Claude-4.6-Opus | 48.29 | 55.13 | 28.91 | 63.26 | 58.51 | 62.65 | 34.07 |
| Qwen-3.5-Plus | 47.27 | 58.52 | 23.21 | 68.88 | 64.36 | 60.69 | 38.80 |
| Doubao-Seed | 46.11 | 55.00 | 24.22 | 62.10 | 65.63 | 56.84 | 32.86 |
| GPT-5.4 | 44.58 | 50.28 | 25.50 | 56.50 | 54.24 | 56.43 | 32.00 |
| Gemini-3.1-Pro | 36.89 | 43.77 | 14.88 | 43.16 | 42.70 | 49.50 | 38.72 |
| Grok-4.1 | 20.54 | 13.71 | 8.00 | 14.19 | 19.70 | 15.90 | 3.20 |
| Kimi-K2.5 | 19.91 | 18.33 | 2.07 | 23.06 | 24.05 | 23.62 | 0.35 |
| GLM-4.5v | 17.13 | 5.43 | 8.61 | 16.17 | -2.97 | 13.60 | -4.34 |
| Open Source General-Purpose MLLMs | |||||||
| Qwen3.5-397B | 44.76 | 53.42 | 22.71 | 62.65 | 57.45 | 56.60 | 35.79 |
| InternVL3-78B | 37.81 | 47.03 | 13.53 | 47.98 | 48.79 | 57.25 | 31.59 |
| InternVL3-8B | 33.07 | 29.49 | 20.30 | 43.41 | 36.23 | 30.48 | 6.66 |
| Qwen2.5-Omni | 32.70 | 30.71 | 18.18 | 36.47 | 40.76 | 34.43 | 8.31 |
| MiniCPM-o | 31.34 | 27.05 | 18.90 | 35.72 | 32.92 | 31.49 | 6.14 |
| Gemma-4-E4B | 27.61 | 28.67 | 9.06 | 39.40 | 32.55 | 31.44 | 10.30 |
| LLaVA-OV-7B | 20.41 | 21.24 | 0.50 | 22.01 | 25.77 | 25.09 | 10.24 |
| Open Source Video-Specific MLLMs | |||||||
| VideoLLaMA3 | 27.18 | 26.82 | 9.90 | 34.37 | 24.55 | 33.76 | 14.02 |
| Video-R1 | 26.73 | 28.41 | 7.21 | 30.50 | 28.70 | 38.49 | 13.87 |
| VideoRFT | 26.13 | 26.17 | 8.17 | 26.50 | 30.14 | 36.04 | 9.01 |
| VideoChat-R1 | 26.08 | 26.49 | 7.77 | 35.87 | 29.05 | 33.04 | 6.46 |
| Video-XL-2 | 24.17 | 29.91 | 0.11 | 28.63 | 29.29 | 40.42 | 19.17 |
| LongVT | 20.51 | 17.14 | 4.64 | 17.99 | 21.61 | 21.92 | 5.02 |
| VideoLLaMA2 | 20.34 | 20.07 | 1.17 | 31.35 | 18.07 | 25.34 | 5.40 |
| AKS | 19.31 | 18.99 | 0.00 | 17.61 | 21.46 | 28.01 | 6.34 |
| Q-Frame | 18.76 | 9.65 | 8.05 | 13.81 | 13.83 | 3.30 | 8.19 |
| VideoChat2 | 17.78 | 15.27 | 0.34 | 17.20 | 14.35 | 18.67 | 10.45 |
| Video-CCAM | 17.53 | 15.10 | 0.00 | 23.38 | 18.31 | 16.92 | 1.05 |
| LongVU | 14.87 | 8.21 | 1.01 | 14.40 | 6.50 | 5.46 | 7.75 |
| TimeChat | 14.42 | 7.79 | 0.34 | 12.27 | 9.66 | 4.61 | 5.04 |
| Random | 13.55 | 0.02 | 6.04 | 0.04 | -0.04 | 0.02 | 0.06 |
Key Findings
F1: Audiovisual-arts reasoning remains far from saturated
The best proprietary model (Claude-4.6-Opus) reaches 48.29% accuracy, trailing human experts (87.18%) by nearly 39 percentage points. Open-source models lag even further behind, underscoring the difficulty of intent-level artistic reasoning for current MLLMs.
F2: Game arts are a shared weakness
Across all model categories, game arts consistently yield the lowest scores, suggesting that game design reasoning (level design intent, mechanics-narrative interplay, aesthetic systems) is uniquely challenging for MLLMs.
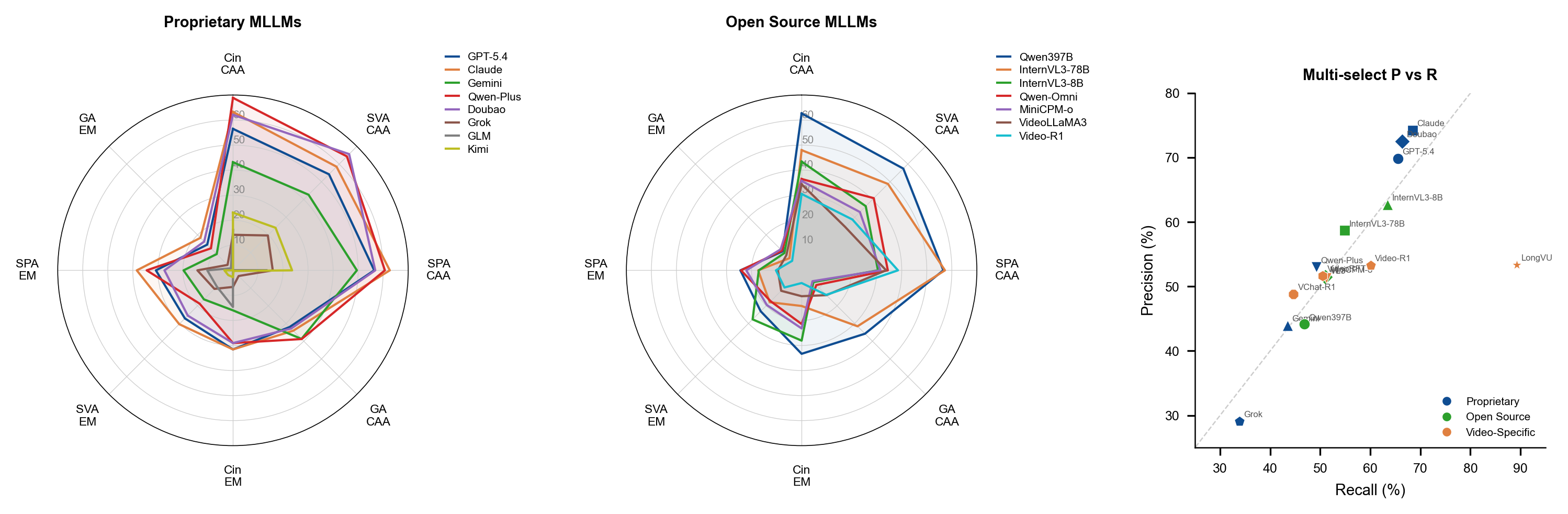
F3: Key frames provide limited gains
Video-specific models that rely on key-frame extraction achieve accuracies between 14.42% and 20.51%, showing that sparse frame sampling is insufficient to capture the temporal and contextual cues essential for artistic understanding.
F4: Models select the most salient correct option but miss the rest
High CAA scores paired with low EM scores reveal that models tend to identify the single most obvious correct answer while failing to recognize additional valid options, indicating shallow pattern matching over genuine comprehension.
F5: Modality gain
Models with audio input (V+A+T) do not consistently outperform vision-text-only (V+T) counterparts, suggesting that current audio encoding and cross-modal fusion strategies fail to effectively leverage auditory information for artistic reasoning.
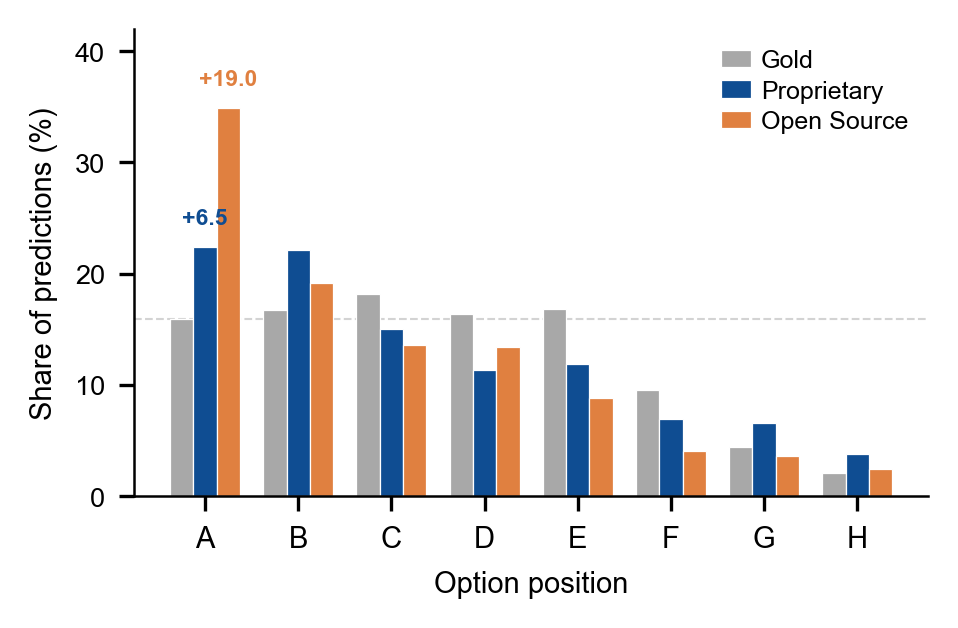
F6: Open-source MLLMs exhibit pronounced first-position bias
Open-source models disproportionately favor answer options in the first position, regardless of correctness. This positional bias inflates accuracy on standard orderings and highlights a systematic vulnerability in multiple-choice reasoning.
BibTeX
If you find MuseBench useful for your research, please consider citing:
@article{fan2026musebench,
title = {MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs},
author = {Fan, Yuxuan and Seo, Gyusik and Hao, Jing and Cho, Jaemin and Bansal, Mohit and Yoon, Jaehong},
year = {2026},
journal = {arXiv preprint arXiv:2606.30026},
url = {https://arxiv.org/abs/2606.30026},
}